Поиск
Найдено: 50
 1ч 20м
1ч 20м📊 Stanford CS234 Reinforcement Learning I Policy Evaluation I 2024 I Lecture 3
1ч 20мМетоды оценки политики: Монте-Карло против Temporal Difference
 1ч 33м
1ч 33м🌊 Йошуа Бенжио: «GFlowNets — это обучаемая замена методам Монте-Карло»
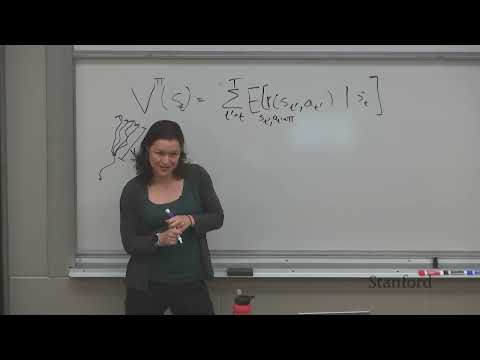 1ч 03м
1ч 03м🔄 Эволюция алгоритмов Actor-Critic: как Стэнфорд обучает нейросети на ошибках
 1ч 24м
1ч 24м🌐 Стэнфордский университет: как устроены энергетические генеративные модели
 1ч 20м
1ч 20м🧠 Стэнфордский курс CS234: принципы офлайн-RL и преодоление неопределенности
 1ч 20м
1ч 20м🎲 Искусство неопределенности: марковские процессы принятия решений в Стэнфорде
 2ч 02м
2ч 02м🤖 Ловушка оптимизации: как ИИ учится и где ошибается
1ч 24м🌌 Стэнфордский курс CS236: Математика и история энергетических моделей ИИ
 1ч 19м
1ч 19м🛡 Стэнфорд о PPO: «Почему это самый полезный метод в RL»
 1ч
1ч🎯 Личный портфель «декана оценки»: Асват Дамодаран о правиле 5% и продаже Nvidia
 58 мин
58 мин🎲 Мэтт Циглер: «План с 50% вероятностью успеха может быть рабочим»
 1ч 08м
1ч 08м🔄 Градиент стратегии и алгоритм REINFORCE: от робототехники до ChatGPT
 19 мин
19 мин🌀 PBS Space Time: как физики воссоздали протон в компьютере
19 минPBS Space Time: «Как мы симулируем квантовую реальность?»
 1ч 56м
1ч 56м🎩 Оз Перлман: «Шарм — это умение сделать так, чтобы другие почувствовали себя привлекательными»
 1ч 06м
1ч 06м🛡 Валидация критических систем в Stanford: как предотвратить катастрофы ИИ и роботов
 32 мин
32 мин🧬 Роуз Ю о «физическом ИИ»: „Нам нужно понимать законы природы“
 32 мин
32 мин📱 Почему концепция Asset Location не работает на практике
 1ч 18м
1ч 18м⚛ Евгений Широков: «Ядерный потенциал — это загадка, которую мы не решили за 90 лет»
 51 мин
51 мин🧩 Сидни Кац: «В валидации безопасности ИИ нет серебряной пули»
 1ч 07м
1ч 07м⚖ Методы Offline RL: от имитации к оптимизации стратегий
 1ч 24м
1ч 24м🌌 Конец времен через 100 миллионов лет: физики переосмысляют циклическую Вселенную
 1ч 15м
1ч 15м📈 Stanford Online: Почему поиск редких отказов в критических системах математически сложен
 1ч 23м
1ч 23м🧠 Обучение ИИ без сэмплирования: как укротить энергетические модели?
 1ч 13м
1ч 13мТеория игр: Minimax, Alpha-Beta и поиск оптимальной стратегии
 1ч 22м
1ч 22м🔄 Профессор Стэнфорда объяснил математику нормализующих потоков и VAE
 1ч 23м
1ч 23м🧠 Авторегрессионные модели: от рекуррентных сетей к трансформерам и MLE
 1ч 35м
1ч 35м🏛 Коннор Танн: как байесовский подход меняет современное машинное обучение
 3ч 09м
3ч 09м🤖 Как RLHF превращает текстовые симуляторы в опасных агентов
 1ч 45м
1ч 45м🧠 Йонас Хюботтер: «Локальное обучение ИИ превосходит огромные модели в 30 раз»
1ч 03м🔄 Stanford Online: «Методы Actor-Critic — база для обучения LLM и роботов»
 1ч 33м
1ч 33м♟ Брайан Ю: «Как мы учим компьютеры играть и думать»
 1ч 51м
1ч 51м🚀 Питер Диамандис: «SpaceX оценивается в $1,75 трлн и строит Dyson Swarm»
 1ч 05м
1ч 05м📉 Бенджамин Феликс и Кэмерон Пэссмор об ожидаемой доходности акций
1ч 23м📐 Обучение энергетических моделей без сэмплирования: от Score Matching до NCE
 52 мин
52 мин🌌 Парадигма космической разведки 3.0: как робот-змея EELS готовится к покорению океана Энцелада
 14 мин
14 мин💰 Девять триллионов в одних руках: как BlackRock подчинил мир?
14 мин📈 BlackRock: архитектура империи и риски тотального влияния
 14 мин
14 мин🎲 Профессиональный счетчик карт о стратегиях, RFID и лазейках в казино
 2ч 16м
2ч 16м🌐 Иллюзия долгосрочных инвестиций: взгляд нобелевского лауреата на рынок
 2ч 04м
2ч 04м⚛ Квантовый Давид против классического Голиафа: как кубиты меняют реальность
 1ч 06м
1ч 06м🌍 Инвестбанки одержимы CTA? Секреты трехэшелонной защиты от Meketa
 38 мин
38 мин🛡 Феликс и Пэссмор: «Почему правило 4% — это путь к банкротству для адептов FIRE»
 2ч 48м
2ч 48м🚶 Почему роботам будущего не нужен тотальный контроль
 1ч 12м
1ч 12м🛠 Стэнфордский курс AA228V: Сидни рассказывает о математическом моделировании критически важных систем
 33 мин
33 мин📉 Разрыв доходности: почему инвесторы в волатильные фонды теряют до 1,44% годовых
 40 мин
40 мин🎙 Бенджамин Феликс: «Рецессия уже в цене, а правило 4% для FIRE — опасный миф»
 36 мин
36 мин🧬 Марти Чавес: «Сделать создателей LLM ответственными за действия пользователей — это как судить Microsoft за ошибки в Windows»
 38 мин
38 мин🎯 Формула Спенсера Кимбалла: как масштабировать стартап до раунда Series F