Поиск
Найдено: 50
 19 мин
19 мин🤖 Обучение на чужих ошибках: Янник Кильхер разбирает бенчмарк D4RL для Offline RL
 49 мин
49 мин🔄 От слепого робопса до Tesla Optimus: как алгоритмы Reinforcement Learning меняют робототехнику
 1ч 19м
1ч 19м🚀 Профессор Бранскилл: «Обучение с подкреплением — это ключ к интеллекту»
 1ч 02м
1ч 02м🤖 Градиент стратегии в Reinforcement Learning: от REINFORCE до Importance Sampling
 26 мин
26 мин🔄 Шмидхубер выворачивает ИИ наизнанку: детальный разбор концепции Upside-Down RL
 1ч 10м
1ч 10м🎮 Профессор Эмма Бранскилл об эволюции алгоритмов исследования в обучении с подкреплением
 37 мин
37 мин🧠 Гокул Свами: «Многие маршруты в Google Maps рассчитываются через инверсное обучение с подкреплением»
 1ч 18м
1ч 18м🤖 От случайного блуждания до Q-Learning: как ИИ учится на своих ошибках
 53 мин
53 мин🚀 Якоб Фёрстер: «RL на GPU — наш момент ImageNet»
 28 мин
28 минCURL: обучение ИИ на «сырых» пикселях без учителя
 1ч 44м
1ч 44м🎮 От Atari до ChatGPT: как ИИ учится на своих ошибках?
 39 мин
39 мин🕹 Как ИИ от DeepMind научился играть в Atari: разбор классической статьи от Янника Килчера
 1ч 13м
1ч 13м🧠 Стэнфордский университет: как самообучение и MCTS сделали AlphaGo непобедимым
 1ч 14м
1ч 14м🚀 Тим Скарфе: «Почему самообучение нейросетей эффективнее человеческой разметки?»
 29 мин
29 минЯнник Килчер: как заставить роботов «думать на ходу»?
 22 мин
22 мин🤖 Заменяет ли простая аугментация годы исследований в сфере RL?
 1ч 18м
1ч 18м🛠 От PPO до Dagger: современные методы обучения агентов
 40 мин
40 мин🤖 Пессимизм как стратегия: Аравинд Раджесваран о безопасности офлайн-обучения ИИ
 44 мин
44 мин🧠 Авторы ChibiT о переносе знаний из текстов Wikipedia в Offline RL
 1ч 02м
1ч 02м🚀 Преподаватель Стэнфорда о методах обучения языковых моделей: от RLHF к DPO
 1ч 48м
1ч 48м🚀 DeepSeek-R1: Как Китай совершил революцию в рассуждениях ИИ
 24 мин
24 минЯнник Килчер о PCGRL: «Дизайн уровня как игра»
 13 мин
13 мин🔄 Дэвид Сильвер о Deep RL: «В нейросетях с миллиардом параметров нет локальных минимумов»
 1ч 25м
1ч 25м🧠 Камьяр Азиззаденешели: интеграция LLM и алгоритмов AlphaGo определит будущее робототехники
 54 мин
54 мин🚀 Эван Рейзер (Poolside): «Обучение на исполнении кода — это путь к созданию AGI»
 1ч 38м
1ч 38м🧠 Харри Валпола: как обучить ИИ планированию и защитить его от системных иллюзий
 24 мин
24 мин🎮 Почему ИИ учится неделями, а человек адаптируется мгновенно?
 2ч 44м
2ч 44м📸 Как победить технологических гигантов: правила игры Кевина Систрома
 3ч 31м
3ч 31м🧠 Как устроены LLM: от «зип-файла интернета» до рассуждающих моделей
 2ч 55м
2ч 55м🤖 Почему ИИ обманывает: инженерный подход к безопасности алгоритмов
 18 мин
18 мин🧱 Как Salesforce Research ускоряет иерархическое обучение с подкреплением через World Graphs
 1ч 05м
1ч 05м🔄 Лекция Стэнфорда о Reward Learning: как научить искусственный интеллект понимать человеческие цели
 47 мин
47 мин🕹 Как классическая игра NetHack помогает обучать нейросети будущего
1ч 02м🔄 Стэнфордский курс CS224R: математический вывод градиентов политики в RL
 1ч 03м
1ч 03м🔄 Stanford Online: «Методы Actor-Critic — база для обучения LLM и роботов»
 1ч 10м
1ч 10м🤖 Курс CS224R в Стэнфорде: разбор многозадачного RL и алгоритма Hindsight Relabeling
 1ч 13м
1ч 13м🧩 Stanford CS234 Reinforcement Learning I Tabular MDP Planning I 2024 I Lecture 2
 52 мин
52 мин🧠 Профессор Челси Финн об основах глубокого обучения с подкреплением в Стэнфорде
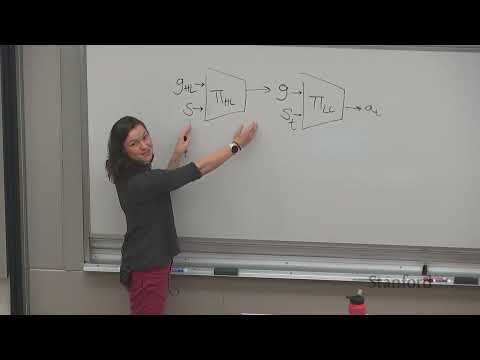 1ч 09м
1ч 09м🏗 Stanford CS224R: Как иерархический ИИ решает задачи с длинным горизонтом
 55 мин
55 мин🧠 Как решать новые задачи в RL без переобучения: разбор Янника Килчера
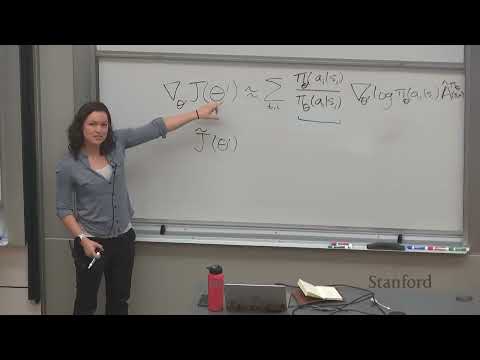 1ч 09м
1ч 09м⚖ Stanford CS224R: PPO и SAC как стандарты обучения с подкреплением
 1ч 14м
1ч 14м⚖ Stanford CS234 Reinforcement Learning I Exploration 1 I 2024 I Lecture 11
 1ч 12м
1ч 12мDREAM: как научить ИИ исследовать и обучаться эффективнее
1ч 03м🔄 Эволюция алгоритмов Actor-Critic: как Стэнфорд обучает нейросети на ошибках
 1ч 22м
1ч 22м🤖 Как глубокое обучение с подкреплением меняет робототехнику и теорию управления
 1ч 20м
1ч 20мМетоды оценки политики: Монте-Карло против Temporal Difference
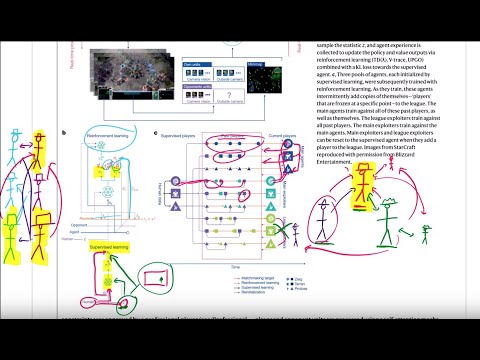 37 мин
37 мин🕹 AlphaStar: как ИИ достиг уровня Grandmaster в StarCraft II
49 мин⚖ Лекция в Стэнфорде: развитие интеллекта роботов через RL
 1ч 18м
1ч 18м🧠 Эмма Бранскилл о DQN: «Реплей-буфер — ключ к прогрессу»
 1ч 07м
1ч 07м🤖 Сергей Левин об эволюции обучения с подкреплением: от «бандитов» в ChatGPT до роботов-трансформеров