Поиск
Найдено: 50
 3ч 59м
3ч 59м🚀 Анатомия нейросетей: фундаментальный гид по теории глубокого обучения
 2ч 25м
2ч 25м🛠 Micrograd: как 150 строк кода объясняют работу современных нейросетей
 1ч 16м
1ч 16м🔄 Лекция CS231N: как устроены нейросети и алгоритм обратного распространения
 3ч 22м
3ч 22м🚀 Как приручить GPU: руководство по конвейерному параллелизму
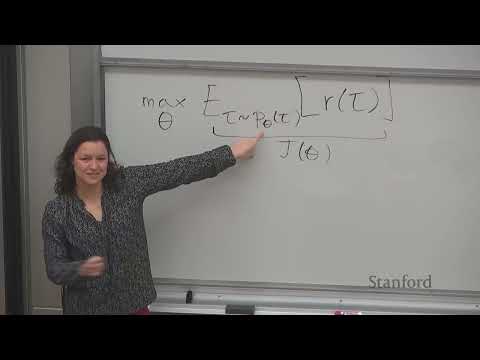 1ч 02м
1ч 02м🔄 Стэнфордский курс CS224R: математический вывод градиентов политики в RL
 1ч 19м
1ч 19м📉 Как Александр Мадри объясняет математику обратного распространения ошибки и концепцию Software 2.0
 1ч 19м
1ч 19м🧩 Эффект Соре: почему домашняя пыль «выбирает» холодные стены?
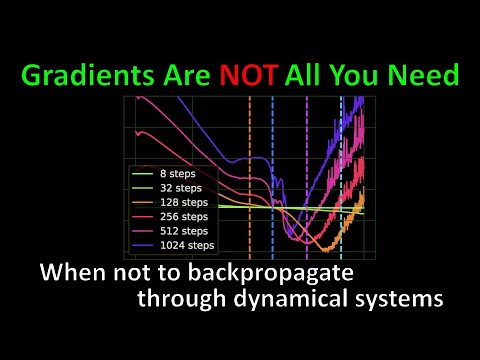 48 мин
48 мин🧠 Янник Килчер: «Градиенты — это не всё, что вам нужно»
 1ч 13м
1ч 13м🎓 Математика глубокого обучения: как устроен алгоритм обратного распространения ошибки
1ч 02м🤖 Градиент стратегии в Reinforcement Learning: от REINFORCE до Importance Sampling
 32 мин
32 мин🧠 Хирургия градиентов: как метод PCGrad решает проблемы многозадачного обучения
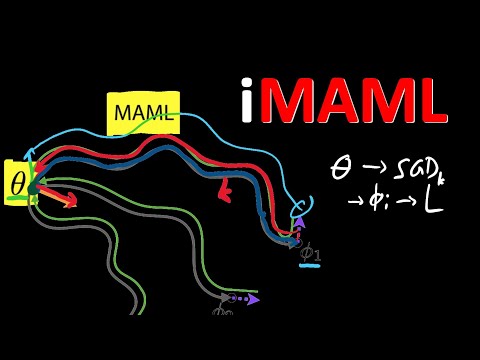 51 мин
51 мин🧠 Как iMAML побеждает вычислительный кошмар традиционного мета-обучения?
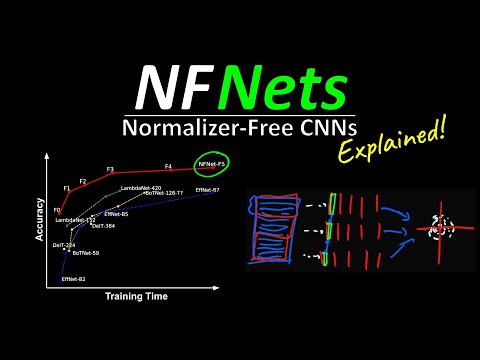 34 мин
34 мин🛑 Кильхер о NFNets: «Примеры внутри пакета остаются неявно взаимосвязанными»
 1ч 11м
1ч 11м🔍 Архитектура RNN и LSTM: разбор лекции CS231N от Стэнфорда
 5ч 48м
5ч 48м🍚 Практический гид по PyTorch: от таблиц до BERT
 45 мин
45 мин🌡 Оптимизация стратегий в RL: три метода оценки градиента от Stanford Online
 1ч 38м
1ч 38м🧪 Профессор Джан Паоло Беретта о законе Онзагера и уравнении Каттанео
 56 мин
56 мин🧠 Как нейросеть SIREN кодирует 3D-пространство и графику через синус
 1ч 23м
1ч 23м📐 Обучение энергетических моделей без сэмплирования: от Score Matching до NCE
 1ч 08м
1ч 08м🔄 Градиент стратегии и алгоритм REINFORCE: от робототехники до ChatGPT
 1ч 17м
1ч 17м📐 Как метод Ньютона преодолевает анизотропию и решает задачи оптимизации
 1ч 19м
1ч 19м🧮 Секреты эффективных LLM: учет ресурсов и оптимизация в PyTorch
 1ч 24м
1ч 24м🌐 Как обучить триллионную модель: гид по параллелизму в ИИ
 32 мин
32 мин🧠 Эффективное неявное дифференцирование: как JAX и Google Research меняют правила игры в ML
 2ч 33м
2ч 33м🛡 Почему безопасность ИИ невозможна: взгляд Николаса Карлини
45 мин🌡 Стэнфорд: три способа научить ИИ принимать решения через оценку градиента
 1ч 11м
1ч 11м🧠 Stanford CS221: «Искусство обучения глубоких нейронных сетей»
 1ч 17м
1ч 17м📊 От RNN к LSTM: как ИИ научился не забывать прошлое
 1ч 21м
1ч 21м🎯 Конец диктатуры правдоподобия: почему в 2023 году ИИ перешел на градиенты?
 52 мин
52 мин🤖 Исследователи из Университета Пердью обучили робота за рекордные сроки с помощью физических априоров дифференциальных уравнений
 53 мин
53 мин🛠 Нейросети вместо формул: почему обучаемые оптимизаторы Google буксуют?
 1ч 13м
1ч 13м🕒 Сэра Бири из MIT об эволюции архитектур памяти нейросетей
 2ч 02м
2ч 02м🧠 Взлом черного ящика: как увидеть алгоритмы внутри нейросетей
 11 мин
11 мин☕ PBS Space Time: как искривление времени порождает гравитацию
 1ч 38м
1ч 38м🌊 Существует ли Четвертый закон термодинамики, управляющий эволюцией природы?
 1ч 06м
1ч 06м🛩 Объяснимость критических систем: как Стэнфордские ученые заглядывают внутрь ИИ
 1ч 13м
1ч 13м🏆 Как заглянуть внутрь ИИ: от теории игр до разреженных автокодировщиков
 1ч 13м
1ч 13м🔄 Подход Model-Based RL: как Стэнфорд обучает сложных роботов за четыре часа
 1ч 21м
1ч 21м🐛 Стивен Бойд: «Вся современная оптимизация свелась к линейной алгебре»
 3ч 15м
3ч 15м🚀 Парадокс целей: почему поиск успеха убивает инновации
1ч 23м🧠 Обучение ИИ без сэмплирования: как укротить энергетические модели?
 1ч 24м
1ч 24м🌌 Стэнфордский курс CS236: Математика и история энергетических моделей ИИ
 1ч 25м
1ч 25м📊 Как зашумление данных помогло диффузионным моделям победить GAN
 1ч 20м
1ч 20м📉 Профессор Стивен Бойд о скрытой выпуклости и глобальных оптимумах
 1ч 11м
1ч 11м🛠 Эволюция архитектур CNN: путеводитель Стэнфорда по глубокому обучению
 41 мин
41 мин🧠 Как научить ИИ размышлять: Андреа Банино о механизмах PonderNet
 39 мин
39 мин🧠 Константин Руш: «Осцилляторы помогают RNN запоминать последовательности до 10 000 шагов»
 1ч 13м
1ч 13м🧠 Лекция Stanford CS221: От табличных методов к Actor-Critic
 14 мин
14 мин🧮 Эндрю Ын: «Самый эффективный способ вычисления производных — справа налево»
 25 мин
25 мин🔍 Как алгоритм Batch Normalization ускоряет обучение глубоких нейросетей